Here’s a quick summary of some of the most interesting autonomous and remote controlled drones out there today. The occasion is that I and 3 others have built a quadcopter drone last semester with the goal to fly it autonomously. While the time we had to finish the project was limited and our project did not reach full autonomous flight just yet we learned a lot about the system and the challenges of such an endeavor. One team member has made the project his diploma thesis and continues to work on the vehicle.


The two images show our drone dubbed B.I.R.D. (Basic intelligent research drone) in flight and the microcontrollers and sensors that control the drone. It is based on the the Mikrokopter project.
Another very interesting drone is the nano air vehicle by AeroVironment. It’s a flapping-wing vehicle for indoors use. Check out this amazing video to see it in action. I’m guessing that while the flapping-wing design is a lot more complicated than the brushless motors in our drone it is more energy efficient.
The third drone I would like to share was built by Armadillo Aerospace. They claim level 2 of the Northrop Grumman Lunar Lander Challenge with it. For more information read on here and be sure to check out this video. Notice how large this vehicle is (can be seen in the end of the video).
The fourth drone is really scary. And it’s not civilian at all. It’s called the Multiple Kill Vehicle and was supposed to shoot down intercontinental rockets in space. The project is apparently canceled but the video is impressive and scary nevertheless. Check it out here.
Update: Researchers at MIT’s Robust Robotics Group have developed a robotic helicopter capable of autonomously flying inside buildings or other GPS-denied environments. Here’s a very interesting video about their project. They achieved what we planned for our project – and I have to say it is very impressive and they did an excellent job.










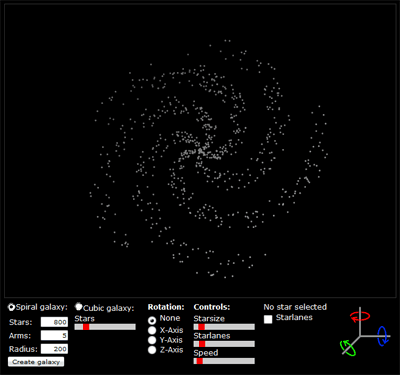
 I wrote a script that creates a pixel tile based map from a random height map and created 6 pixel tiles for the different heights. I wanted water, a beach, nice grasslands and icy mountains. To generate the height map I used Matlab. I tried a couple of different techniques and finally ended up using a
I wrote a script that creates a pixel tile based map from a random height map and created 6 pixel tiles for the different heights. I wanted water, a beach, nice grasslands and icy mountains. To generate the height map I used Matlab. I tried a couple of different techniques and finally ended up using a 




{kind=link}
{kind=link}
{kind=link}
{kind=link}